
Beyond the Cloud: Distributed AI and On-Device Intelligence
Transition of AI workflows from cloud to the edge with specialized chip infrastructure & models, multi-modality and ambience across devices

TL;DR
Today, we’re going beyond the cloud, to the device, removing those fundamental constraints of power and space, reducing latency, ensuring privacy. We believe AI will be distributed. The richest AI experiences will harness the power of cloud and the edge, working together, in concert. This in turn will lead to a new category of devices that turn the world itself into a prompt. Devices that can instantly see us, hear us, reason about our intent and our surroundings
The above is the opening line from Satya Nadella's recent keynote for the launch of a Windows PC tailored to AI. The new and improved Windows OS and laptop design claims to be 58% more performant and have 20% more battery life than the latest MacBook Air while processing state-of-the-art AI workloads. The event was perfectly timed two weeks prior to Apple's WWDC, where Apple is expected to unveil native AI features embedded within iOS 18 through Siri, Search, and Safari. The following trends are very clear:
Small Language Models: The advent of smaller language models is intended to act as a local semantic kernel that can run on the device, understand and process the user’s screen context, and handle queries to a certain extent while delegating complex user queries to the cloud model.
Cloud to the Edge: Part of the AI community is shifting from a pure cloud-based Model-as-a-Service approach to a hybrid approach including local multi-modal AI workloads interfacing with cloud hosted models. This approach leverages an ensemble of open-source and closed models based on the nature of input and complexity of the task at hand.
Specialized Chips for Local AI Workloads: While companies such as Groq provide lightning-fast inference speeds on the cloud, the need for specialized chips for on-device processing is gaining momentum. Big tech and major chip manufacturers are partnering to bring state-of-the-art neural chip architectures to run local AI workflows in a low-latency, battery-efficient, and secure manner.
Omni-Modality & Device Ambience: Model architectures are transitioning to uniformly tokenize multiple modalities of input, including text, images, voice, and video. They process them using an ensemble or sometimes a single model architecture while exposing such services across laptops, phones, tablets, and smart glasses. This leverages all sources of the user’s environmental context, creating ambient services that users can take anywhere and deeply interact with.
Multi-Modal SLMs deployed locally on devices
The core benefits that SLMs claim to offer over LLMs are reduced latency and higher data security due to on-device processing. However, this comes with trade-offs in battery life, compute constraints, and intelligence constraints. Notable recent model releases include:
Phi 3-Silica from Microsoft: With 3.3 billion parameters, this latest release from the Phi 3 small language model series is optimized to work with Microsoft NPUs designed specifically for co-pilots and PCs. Phi 3 claims to outperform GPT-3.5 with far fewer parameters, has a token latency of 650 tokens/s, and leverages 1.5 W of power. It signals progress in deploying SLMs locally on optimized end-user hardware.
Apple ReaLM: This hybrid architecture deploys a smaller language model fine-tuned on reference resolution tasks such as a user’s active screen, conversational history, and background processes that serve as multiple signals of context. It creates diverse context representations sent to OpenAI’s models for comprehensive responses. This is targeted at maximizing user experience by deeply understanding user’s screen context and getting better responses, possibly from cloud hosted LLMs to create a hybrid approach towards building useful AI functionalities within Apple devices.
Google Gemini Nano: This multi-modal on-device foundational model aims to make the end-user experience faster and more secure. It is currently catered towards locally processed audio calls for spam detection, improving accessibility via TalkBack, etc. that make for useful functionalities for the Google Pixel.
Stable Diffusion 3 Partnership with Argmax: Deployed via DiffusionKit for on-device inference on Mac, this model is optimized for memory consumption and latency for both MLX and Core ML (frameworks for running machine learning on Apple silicon) and showcases Stability AI’s investment in on-device model execution frameworks.
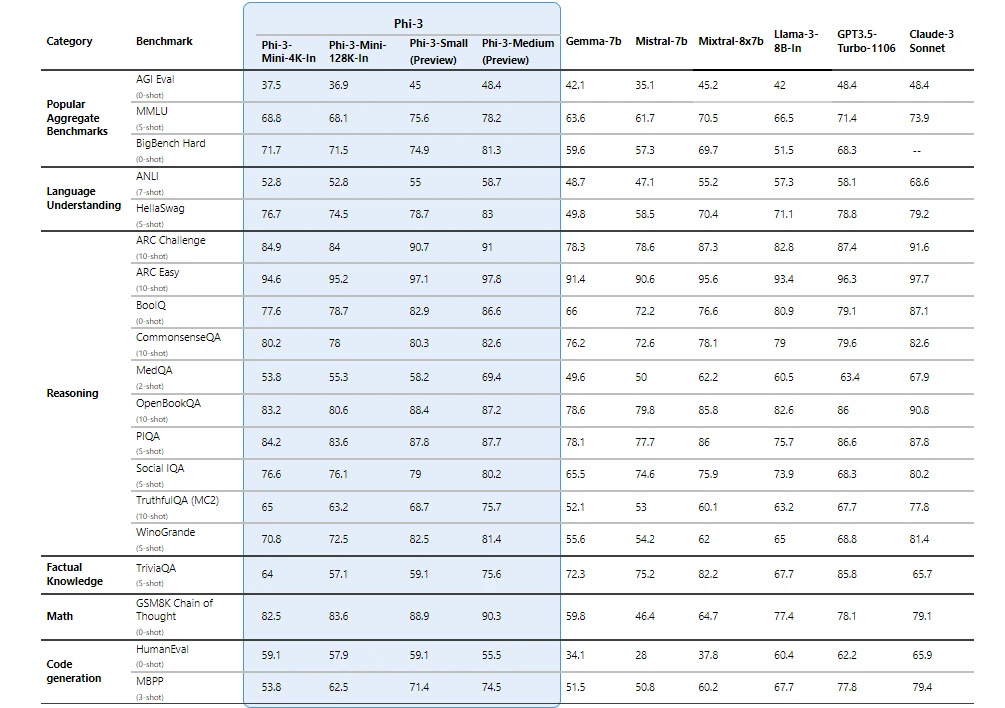
On-device end user apps deployed across multiple devices
Now that we’ve discussed the underlying models powering the end-user context layer, it’s important to understand how this context is gathered via various device sensors. Local agents view what the user views by capturing their screen context alongside the camera and microphone feed for external audio and video when prompted. They process multiple modalities of inputs in real-time, running inference quickly to provide a low latency user experience. Here are a few latest announcements:
ChatGPT-4o: The latest launch announced a local desktop client that can watch a user screen and help with various use cases such as summarizing code, analyzing complex charts, or assisting with math problems. One of the demos showcased ChatGPT’s capability to watch a live video feed from a tablet camera and explain the solution to the user in real time with minimal latency. This signals the power of an omni-modal model service interfacing via a local desktop client with low-latency video & user screen inputs. Creating useful desktop clients that can not only chat with the user, but also watch the user’s screen, gather video via device cameras, while sending high bandwidth information in real time to the core model service facilitates seamless human-machine interaction.
On-Screen Widgets: In the latest Android keynote, Google introduced the “AI at the Core” initiative for Android, that includes functionalities such as “Circle to Search” and context-aware features by overlaying the Gemini assistant on top of existing apps to seamlessly switch back and forth between the app and the assistant. Google also claims to release the capability for Gemini Nano to analyze the content of active applications on a user’s screen to provide relevant suggestions in the upcoming months. This is similar to the ChatGPT-4o desktop client, but implemented keeping mobile form factor in mind, making it easy for users to retrieve information with minimal context switching.
Meta’s Ray-Bans’s latest multi-modal AI upgrade: This has turned out to be a surprising success for consumers, as the glasses can see exactly what the user sees through the embedded camera. While the AI assistant largely uses a Bluetooth connection to a mobile device, leveraging the mobile internet to interface with Meta’s hosted Llama models, the core value-add comes from the capability to summon the model intuitively via voice and interact with the assistant in real-time through audio and video feed. This sets the precedent for how AI agents can become much more ambient across our real and virtual world.
In the existing architectures leveraged for various device types, we’re noticing deeper OS level integrations for the SLMs exposing various on-device components while giving them the flexibility to interface with end users via lightweight client applications supported across multiple devices. However, we may see see more powerful on-device models that increasingly reduce the need for interfacing with cloud LLMs, processing complex user queries locally while keeping user data more secure and minimizing latency.
Specialized Chipsets
While Nvidia's data center revenue in Q2 2024 has continued to surge with increasing gross margins due to growing demand for AI training and a lot more inference, we’re starting to see several hyperscalers build out or advance their own chipset initiatives with Google Trillium, AWS Trainium v2, Meta MTIA. While lot of chip-level innovation seems to be shifting from training to inference, at the same time, we’re also observing various innovations for on-device chips optimized for local AI workloads.
Microsoft’s Neural Processing Unit (NPU): This power-efficient local chipset can run voice recognition, image generation, and various other tasks on the edge while complementing CPUs and GPUs on the latest Microsoft Windows PCs, that claims to run a variety of small language models locally.
Apple’s latest M4 chip: This release claims to have the fastest neural processing engine, paving the way for various on-device machine learning operations that Apple may announce for Siri and Search at WWDC 24. Apple currently uses this on the iPad Pro, but we may see variants of this chip leveraged for MacBooks and eventually the iPhone, which is where Apple may release a plethora of AI-native features across Siri, Search, and Safari.
Google Tensor G3: Powers Pixel 8, claimed to locally execute the same text-to-speech model that Google has historically used in the cloud, and runs twice as many machine learning models on-device for various use cases.
Several other manufacturers are competing to bring on-device chips to market for local AI workloads including AMD with its Ryzen 7040 series of notebook processors, as well as Samsung and LG for their consumer grade mobile devices. NVIDIA is also speculated to join the party by preparing a system-on-chip (SoC) that pairs Arm's Cortex-X5 core design with GPUs based on its own recently introduced Blackwell architecture. It signals a strategy shift from the Grace ARM CPU design focussing on data center applications to datacenter applications, to get a greater slice of the AI PC market, coalescing around CPUs with built-in AI acceleration.
From Multi-Modality to Omni-Modality
The latest release of ChatGPT-4o, which can reason across text, audio, and video in real-time in a fast and natively multi-modal way while detecting emotion in voice input, clearly marks an evolution in input encoder architectures, giving them a new name: "Multimodal Unified Token Transformers (MUTTs)". This signifies an evolution from single large monolithic models used separately based on prompt inputs to a micro-services style muli-modal model ensemble that can process various modalities
Meta’s introduction of Chameleon, a mixed-modal early-fusion foundation model similar to GPT-4o, capable of interleaved text and image understanding and generation, also signals a shift in the research communities towards an early fusion multimodal approach.
Open Questions & Constraints
While the progress for on-device assistants looks very promising and is backed by real model releases, device rollouts, and meaningful demos, the following aspects are yet to be fully addressed:
Intelligence Constraints: While small language models have shown promising performance on various benchmarks with a smaller number of parameters, they’re still far from the benchmarks of state-of-the-art large language models (LLMs) with medium to high parameter counts. Initially, the consensus was to scale data, compute, and parameters in a coordinated fashion in line with Chinchilla optimal scaling. However, more recently, it has become evident that for deployment efficiency, it’s more useful to focus on big compute and data for much smaller models. Meta's Llama-3 8b was almost as powerful as the biggest version of Llama 2. Phi-3 mini with 3.8 billion parameters was trained on 3.3 trillion tokens of high-quality data with extensive post-training, paving the path for future model evolution.
Battery Constraints: While the models have become smaller and are running on optimized chipsets, battery usage remains a significant trade-off. Although Phi 3 has promising battery usage claims, long-term performance versus battery consumption is yet to be seen.
Compute Constraints: While the inference speeds for Phi 3 are stated at 650 tokens/s, the small language model community as a whole is yet to see broader community-built end-user applications beyond those created by Google and Microsoft. This will help determine how latency problems are broadly solved by the open-source community on a broader set of small language models.
The Bull Case
From an optimistic perspective, the following factors may lead to large-scale adoption of SLMs (Small Language Models) locally deployed on devices:
Advancements in Research: As research progresses in finding high-quality data sets to train models with fewer parameters, we could potentially see smaller parameter models (< 1 billion) achieving accuracy benchmarks comparable to existing state-of-the-art (SOTA) large language models (LLMs).
Chipset Efficiency: Chipsets may become smaller and more efficient at handling higher magnitudes of computation. This could enable them to run even larger language models locally on consumer devices such as phones, tablets, and smart glasses.
Battery Improvements: Batteries in PCs, tablets, mobile phones, and smart glasses may become more powerful without changing form factors, allowing both small and large models to run with acceptable inference speeds and minimal power drain.
The Bear Case
Looking at future evolution from a different perspective:
Historical Trends in Cloud Computing: During the rise of cloud computing, many companies provided on-premises "cloud API proxies" or appliances for creating on-premises clouds. While infrastructure companies like Nutanix and Cisco had emerging products in this space, the value consolidated to the cloud hyper-scalers. A similar trend could apply to LLMs, potentially reducing the value of SLMs.
Increasing Power of Cloud-Hosted Models: Cloud-hosted models may become increasingly powerful compared to SLMs, making the trade-off for deploying SLMs less attractive. This could be further emphasized by significant improvements in network bandwidths and data center computing capabilities, reducing network latency and inference speeds, thereby decreasing the need for locally executed AI workloads.
Ultimately, the decision between LLMs and SLMs will depend on specific use cases, security requirements, latency, power usage, and user experience considerations.